-
[R 데이터 분석] 분류모형, 서포트 벡터 머신 (SVM) 분석머신러닝 with R 2019. 9. 18. 17:38
서포트 벡터 머신 (Support Vector Machine, SVM)이란?
- 지도학습 알고리즘 중 하나로 데이터 분류를 위한 모형
- 확률(p)과 가정을 사용하지 X, 오직 공간상의 정보(선)으로만 이진 분류
- 두 클래스(○ & ■) 사이에 마진(margin)이 최대가 되는 선 "하이퍼플레인"을 그어 분류
- ○ 와 ■ 를 어떻게 가장 잘 자를 것인가? margin을 최대화 하는 알고리즘!

[참고] https://ratsgo.github.io/machine%20learning/2017/05/23/SVM/ SVM의 특징
- 기하학적 모형 (거리 정보만 이용)
- 확률값을 제공하지 않는 Hard classification !
- 확률로 계산하는 분류를 soft classification이라고 함. (정보를 더 많이 가지지만 만들기가 더 어려움)
- 커널 함수를 사용할 수 있어 비선형에도 적용 가능함. (확장성이 좋음)
하이퍼플래인(hyperplane) 이란?
데이터를 두개의 집단으로 나누는 모형으로, 데이터의 차원(n)보다 한 차원 낮은 (n-1) 차원의 평면을 이용해 목표변수를 분류한다.
즉, 2차원의 데이터의 경우 hyperplane은 1차원의 선, 3차원 데이터의 경우 hyperplane은 2차원의 면으로 데이터를 2개의 집단으로 분류한다.
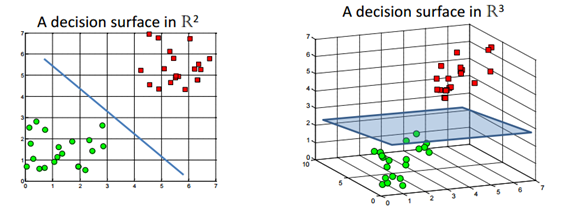
[참고] https://wikidocs.net/5719 그렇다면 가장 최적의 하이퍼 플래인을 찾는 방법은 무엇일까?
이분형 데이터로 분류하는 하이퍼 플레인은 여러개가 될 수 있다. 하이퍼 플래인과 가장 가까운 점과의 수직선의 거리를 마진으로 정의하고, 이 값이 가장 큰 것으로 선택한다. --> Max(margine)
하지만 위 그림들 처럼 두 집단이 완벽하게 분리되지 않는 경우가 훨씬 일반적이다.
따라서 몇몇 점들은 하이퍼 플래인을 넘어가는 것을 허용해야 한다. 즉, 마진을 최대화 하면서 몇몇 분류가 안된 점들의 거리를 최소화함으로써 가장 최적의 하이퍼 플래인을 찾는 것이다 (soft-margin). 하이퍼 플래인을 넘어가는 점들에 패널티를 부과하여 패널티를 최소화 한다. 패널티 값은 cross validation을 통해 도출 할 수 있다.
비선형 분류를 위한 커널 트릭
선형분류만 할 수 있는 SVM에 커널 함수를 적용하여 비선형 분류를 할 수 있도록 데이터의 공간을 변형하는 것이 "커널트릭" 이다. 트릭이라는 말에서 알 수 있듯이, 커널을 통해 공간을 잠깐 변형시켰다가 다시 원래대로 복귀 시키는 것이다. 이를 통해 다음 그림과 같은 데이터를 쉽게 두 개의 집단으로 분류 할 수 있다. 주요 변형 방법에는 polynominal kernel (다항식)과 Gaussian Radial Kenel (지수분포) 등이 있다. 어떤 커널을 사용할 지는 각각의 방법들을 모두 시행한 후 가장 좋은 파라미터를 찾아야 한다.
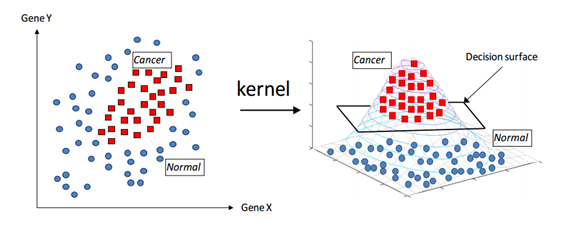
[참고] https://wikidocs.net/5719 SVM의 장단점
장점
- 분포의 가정이 없기 때문에 어떤 데이터에도 적용이 가능
- 예측 정확도가 높음 (단일 모형 대비)
- 노이즈에 크게 영향을 받지 않으며, 오버피팅 될 가능성이 낮음
단점
- 데이터셋이 클 수록 속도가 매우 느려짐 (메모리 크기에 따라 달라질 수 있음)
- 커널을 사용할 경우에도 계산량이 커져 속도가 더 느려짐
- 어떤 커널이 좋은지 선택하기 어려움
- 고차원으로 갈 수록 해석이 어려워짐
[참고] 실무에서 써먹는 머신러닝 with R
반응형'머신러닝 with R' 카테고리의 다른 글
머신러닝(machine learning)의 기본 개념과 원리 (인공지능 vs. 머신러닝 vs. 딥러닝) (0) 2020.02.22 [R 데이터 분석] 나이브 베이즈 분류 (Naive Bayes Classification) (0) 2019.11.03 [R 데이터 분석] 최근접 이웃 (K-Nearest Neighbor, KNN) 분석 (0) 2019.09.15 [R 데이터 분석] 연관성 분석 (Association Rules), 장바구니 분석 (0) 2019.09.08 [R 데이터 분석] 밀도기반 군집분석 (DBSCAN, Density-Based Spatial Clustering of Applications with Noise) (0) 2019.09.06