-
[R 데이터 분석] 최근접 이웃 (K-Nearest Neighbor, KNN) 분석머신러닝 with R 2019. 9. 15. 19:49
최근접 이웃 분석이란?
'유유상종' 의 의미를 연상하면 된다.
입력 변수간의 거리를 구하여 가장 가까운 k개의 데이터를 최근접 이웃으로 정하고, 이를 기반으로 목표변수의 범주를 정하는 알고리즘이다.
KNN 분석은 어떻게 보면 k-means 분석과 비슷해 보일 수 있는데 둘은 완전 다른 알고리즘이다. k-means는 군집을 위한 알고리즘이고 KNN은 분류를 위한 알고리즘이라고 보면 된다.
군집분석을 통해서 우리가 알고 싶은 변수가 정확해진 후, 그것을 분류해 내는 것이 의미가 있다면, 그 때 카테고리 중 하나를 target으로 정의해서 이후 분류 알고리즘을 적용한다. 군집분석은 탐색적인 목적으로 분류 알고리즘을 사용하기 전에 어떤 데이터 집단이 있는지 확인할 때 많이 사용 된다.
*** 군집 분석과 분류의 차이 ***
군집분석은 비지도 학습으로 학습데이터에 정답이 없다. 군집분석의 데이터는 입력변수 등이 유사한것 끼리 묶어 주기 때문에 사전에 정의된 카테고리가 없고 목표변수의 정답이 없어 정확히 분류했는지를 평가하는 것이 불가능 하다.
분류(classification)는 지도학습으로 학습 데이터가 정답을 가지고 있다. 즉, 사전에 정의된 카테고리를 주어진 입력변수(x1, x2, ....)로 모형을 생성하는 것이다.
KNN분석의 특징
학습데이터 셋과 데이터 간의 '거리' 만을 사용하여 분류하기 때문에 분류를 위한 수식이 필요 없다.
이것을 게으른 학습(lazi training) 혹은 인스턴스 기반 학습(instance based training) 이라고 부른다.
최근접 이웃 분석은 가장 간단한 기계 학습 알고리즘이다.
분류 방법
초록색 ●은 네모로 분류되어야 하는가? 세모로 분류되어야 하는가?
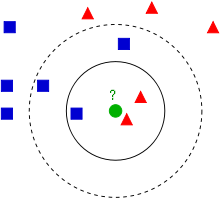
[참조] https://ko.wikipedia.org/wiki/K-%EC%B5%9C%EA%B7%BC%EC%A0%91_%EC%9D%B4%EC%9B%83_%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98 - K를 기반으로 선택
- k = 3 이면 실선을 기준으로
- ■은 1개로, 확률 = 1/3
- ▲은 2개로, 확률 = 2/3
- ● 은 ▲ 로 분류됨
- k = 5 이면 점선을 기준으로
- ■은 1개로, 확률 = 3/5
- ▲은 2개로, 확률 = 2/5
- ● 은 ■ 로 분류됨
- 이상치 방법
- 지역적으로 가장 가까운 K개의 점들과 거리를 요약 (평균)
- 전체 집단과 가장 멀리 떨어진 개체를 도출하여 전역적 이상치 (global outlier)를 도출
- target이 없는 경우 특정 개체와 유사한 개체를 도출
- 모든 점들과 거리 행렬이 생성됨
- 각각의 모든 개체 (raw)에 대해 k개의 이웃 리스트와 거리 제공
- → 특정 개체와 가장 가까운 리스트가 도출
- but 유사한 집단에 유사한 문제가 있을 수 있음.
실습
- DATA: Pima.tr & Pima.te (in MASS package)
- 532명의 피마 인디안 여성의 당뇨병 진단
- npreg: 임신횟수
- glu: 구강 포도당 내성 건사에서 혈장 포도당 농도
- bp: 확장기 혈압 (mm Hg)
- skin: 삼두근 피하 지방 두께 (mm)
- bmi: 체질량 지수
- ped: 당뇨 가족력 함수
- age: 연령
- type: 당뇨병 여부 (yes or no)
- FNN package 의 KNN 사용
- 빠른 속도, 이웃의 ID 및 거리 정보 제공
- 거리를 생성하기 때문에 변수의 표준화 필요
- 분류를 평가하는 지표로 모형 평가
- 532명의 피마 인디안 여성의 당뇨병 진단
#최근접이웃 #packages install if (require("FNN") == F) install.packages("FNN") # for KNN & get.knn if (require("MASS") == F) install.packages("MASS") # for data set pima.tr & pima.te if (require("caret") == F) install.packages("caret") # for k optimazation install.packages('e1071', dependencies = TRUE) library(FNN) library(MASS) library(caret) library(dplyr) library(e1071) library(ROCR) set.seed(1234) # 피마 인다안 여성 성인 당뇨병 532명 데이터 셋 data(Pima.tr) data(Pima.te) # npreg : 임신 횟수 # glu : 구강 포도당 내성 검사에서 혈장 포도당 농도 # bp : 확장기 혈압(mm Hg) # skin : 삼두근 피하 지방 두께 (mm) # bmi : 체질량지수 # ped : 당뇨 가족력 함수 # age : 연령 # type : 당뇨병 여부 (Yes or No) str(Pima.tr) str(Pima.te) # 변수의 단위 표준화 ## 데이터셋 구분변수 생성 (학습용, 테스트용) Pima.tr$flag <- "tr" Pima.te$flag <- "te" #데이터 합치기 (학습 + 테스트) Pima <- bind_rows(Pima.tr,Pima.te) ## 표준화 Pima_scale <- as.data.frame(scale(Pima[,c("npreg","glu","bp","skin","bmi","ped","age")])) Pima_scale$type <- Pima$type Pima_scale$flag <- Pima$flag # 파라메터 학습 (K 를 2~30개 까지 ) grid <- expand.grid(.k = seq(2,30, by =1)) control <- trainControl(method = "cv") knn.train <- train(data = Pima_scale[Pima_scale$flag == "tr",-9], type~., method = "knn", trControl = control, tuneGrid = grid) plot(knn.train) # k가 14개 일때 가장 정확 knn.test <- knn(Pima_scale[Pima_scale$flag == "tr",-(8:9)], Pima_scale[Pima_scale$flag == "te",-(8:9)], Pima_scale[Pima_scale$flag == "tr",8], k = 14, prob = T ) str(knn.test) head(knn.test) head(attr(knn.test, "prob")) head(attr(knn.test, "nn.dist")) head(attr(knn.test, "nn.index")) # 성능 평가 ## prediction_result value Pima.te$KNN_prd <- attr(knn.test, "prob") Pima.te$KNN_r <- knn.test temp <- table(Pima.te$KNN_r, Pima.te$type) # confusion table # roc curve & auroc pred_knn <- prediction(Pima.te$KNN_prd , ifelse(Pima.te$type == "Yes",0,1) ) perf_knn <- performance(pred_knn,measure = "tpr", x.measure = "fpr") plot(perf_knn, col ="blue", main = "ROC Curve") abline(0,1) # accuracy check result_summary <- data.frame( modle = "KNN", accuracy = (temp[1,1] + temp[2,2]) /sum(temp) , precision = temp[2,2] / (temp[2,1] + temp[2,2]), recall = temp[2,2] / (temp[1,2] + temp[2,2]), AUROC = performance(pred_knn,"auc")@y.values[[1]]) result_summary <- result_summary %>% mutate(F1 = 2 * precision * recall /(precision + recall)) print(result_summary)[참고]
실무에서 써먹는 머신러닝 with R
위키피디아: K-최근접 이웃 알고리즘
반응형'머신러닝 with R' 카테고리의 다른 글
[R 데이터 분석] 나이브 베이즈 분류 (Naive Bayes Classification) (0) 2019.11.03 [R 데이터 분석] 분류모형, 서포트 벡터 머신 (SVM) 분석 (1) 2019.09.18 [R 데이터 분석] 연관성 분석 (Association Rules), 장바구니 분석 (0) 2019.09.08 [R 데이터 분석] 밀도기반 군집분석 (DBSCAN, Density-Based Spatial Clustering of Applications with Noise) (0) 2019.09.06 [R 데이터분석] k - 평균(k-means) 군집 분석 (0) 2019.09.02 - k = 3 이면 실선을 기준으로