-
R 데이터 정제/ 결측치 및 이상치 제거하기머신러닝 with R 2019. 7. 18. 14:54
결측치(Missing Value) 란,
누락된 값, 비어있는 값을 의미하고 이러한 값은 함수 적용이 불가하며 분석 결과를 왜곡시킨다.
따라서 결측 값을 제거 후에 분석을 실시하는 게 좋다.
결측치는 보통 NA 라고 표기하며 작은따옴표나 큰 따옴표를 붙이지 않는다.
결측치를 확인할 때는
is.na(데이터프레임 명칭)
ex) is.na(df)
결측치의 빈도를 출력할 때에는
table(is.na(데이터 프레임 명칭))이라는 함수를 사용한다.
ex) table(is.na(df))
결측치를 포함한 상태로 mean( ), sum( )과 같은 분석을 실시하면,
결과 값에 NA라고 뜨면서 제대로 값을 산출하지 못한다.
따라서 결측치가 있는 행을 제거한 후 분석을 실시해야 한다.
결측치를 제외 할 때에는 filter(! is.na())를 활용하거나 na.omit( )을 사용하여 모든 변수에 결측치가 없는 데이터만 출력할 수 있다.
ex)
df_nomiss <- df %>% filter(!is.na(score))
df_nomiss2 <- na.omit(df)
뿐만 아니라 함수를 사용할 때 결측치 제외 기능을 사용할 수 있는데 na.rm = T라는 옵션을 달아 주면 된다.
예를 들어 df라는 데이터 프레임의 score 변수에 있는 결측치를 제외하고 평균을 산출할 때에
mean(df$score, na.rm = T)를 하면 결측치를 제거한 score의 평균값을 산출할 수 있다.
하지만 이때 주의할 점은 결측치가 많은 경우, 모두 제외하게 되면 데이터 손실이 커져 오차가 커질 수 있다.
따라서 다른 값을 대체하여 채워 넣는 것이 좋은데 대표적인 결측치 대체법으로
1) 대푯값(평균, 최빈값 등)으로 일괄 대체
2) 통계분석 기법을 적용하여 예측값 추정하여 대체
하는 방법이 있다.
mpg 데이터를 활용해 예시를 공부해보자.
우선 mpg 데이터 원본에는 결측치가 없기 때문에 몇 개의 값을 결측치로 만들고 시작할 것이다.
drv(구동방식) 별로 hwy(고속도로 연비) 평균이 어떻게 다른지 알아보려고 한다. 따라서 먼저 두 변수에 결측치가 있는지 확인해보고 있다면 결측치를 제거한 후, 어떤 구동방식의 hwy 평균이 높은지 알아보자.
mpg <- as.data.frame(ggplot2::mpg) mpg[c(65, 124, 131, 153, 212), "hwy"] <- NA table(is.na(mpg$drv)) table(is.na(mpg$hwy)) mpg %>% filter(!is.na(hwy)) %>% group_by(drv) %>% summarise(mean_hwy = mean(hwy))
drv에는 결측값이 없어 hwy에 있는 결측값만 제거 후 분석 실행 데이터 분석 시에 결과 값에 영향을 미치게 되는 값이 결측치 외에 한 가지가 더 있다.
바로 정상 범주에서 크게 벗어난 값인 이상치(Outlier)이다.
이상치 역시 분석 결과를 왜곡시키기 때문에 결측 처리 후에 제외하고 분석해야 좀 더 정확한 결과를 가져올 수 있다.
이상치의 종류에는 대표적으로 두 가지가 있는데, 아예 존재할 수 없는 값 혹은 극단적인 값이다.
전자의 예로는 성별 변수에 3이라는 값이 들어간 것이며, 후자의 예로는 몸무게 변수에 200이라는 값이 들어간 것이다.
성별 변수에 3이라는 값이 들어간 것은 논리적으로 존재할 수 없으므로 바로 결측 처리를 하고, 몸무게 변수에 200이라는 값이 들어갔으면, 정상 범위의 기준을 정해서 결측 처리를 함으로써 해결할 수 있다.
그렇다면 극단치의 기준은 어떻게 정할까?
통계적으로는 상하위 0.3% 나 상자 그림 1.5 IQR을 벗어나면 극단치로 판단한다.
mpg 데이터로 예를 들어보자.
mpg <- as.data.frame(ggplot2::mpg) boxplot(mpg$hwy) boxplot(mpg$hwy)$stats #상자그림 통계치 출력[출처] 실무에서 써먹는 머신러닝 (with R) 위의 상자 그림에서, 상자 밖 가로선이 극단치의 경계(Q1, Q3 밖 1.5 IQR 내 최댓값)를 의미하며, 이 선 밖에 있는 동그라미 표식이 극단치(Q1, Q3 밖 1.5 IQR을 벗어난 값)인 것이다.
상자 그림의 통계치 결과를 확인하면, 12~37을 벗어난 값을 극단 치라고 설정할 수 있고, 이 값에 NA(결측치)를 할당하면 된다. 이 결측치를 제외하고 drv 별 hwy 평균값을 구하는 코드는 다음과 같다.
mpg$hwy <- ifelse(mpg$hwy <12 | mpg$hwy > 37, NA, mpg$hwy) table(is.na(mpg$hwy)) mpg %>% group_by(drv) %>% summarise(mean_hwy = mean(hwy, na.rm = T))[mpg 데이터 활용하기]
일부러 이상치 만들고 시작.
1) drv에 이상치 있는지 확인 후 있다면 결측 처리(% in% 활용). 이상치 사라졌는지 다시 확인.
2) 상자 그림 이용해서 cty의 이상치 확인 및 상자그림 통계치 이용해 결측 처리한 후 다시 상자 그림으로 확인.

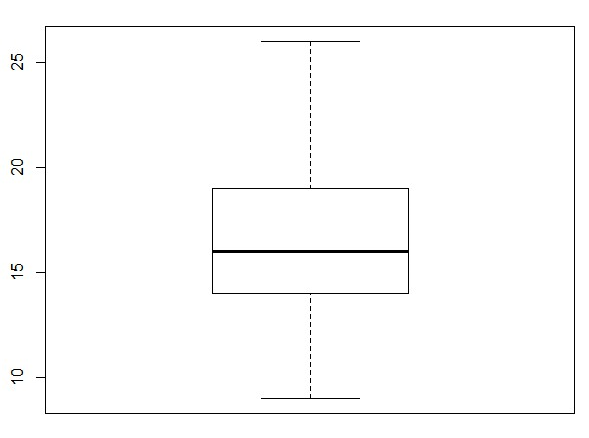
3) 이상치 제외한 후 drv 별로 cty 평균이 어떻게 다른지 알아보기
#이상치 만들기 mpg <- as.data.frame(ggplot2::mpg) mpg[c(10,14,58,93), "drv"] <- "k" mpg[c(29, 43, 129, 203), "cty"] <- c(3,4,39,42) table(mpg$drv) #이상치 확인 #drv가 4, f, r이면 기존 유지, 그 외 NA 할당 mpg$drv <- ifelse(mpg$drv %in% c("4", "f", "r"), mpg$drv, NA) table(mpg$drv) #이상치 확인 boxplot(mpg$cty)$stats #상자 그림 생성 및 통계치 산출 #9~26 벗어나면 NA 할당 mpg$cty <- ifelse(mpg$cty <9 | mpg$cty > 26, NA, mpg$cty) boxplot(mpg$cty) #상자그림 생성 #3번 문제 mpg %>% filter(!is.na(drv) & !is.na(cty)) %>% group_by(drv) %>% summarise(cty_mean = mean(cty))반응형'머신러닝 with R' 카테고리의 다른 글
R 데이터 마이닝 '의사결정 나무 (Decision Tree)'란? (5) 2019.07.23 R 기계학습 모델링 기법 및 알고리즘 (지도학습, 비지도학습, 분류모델, 추정모델, 군집모델, 연관성 모델) (0) 2019.07.22 자유자재로 데이터 가공하기2. 데이터 전처리/ dplyr 패키지/mpg 데이터 심화 활용 (0) 2019.07.18 자유자재로 데이터 가공하기 1. 데이터 전처리 dplyr 패키지 (0) 2019.07.17 R 데이터 분석의 기초 2. 데이터 수정하기 / 변수 이름 바꾸기/ 파생 변수 생성/ 조건문 ifelse 활용 (예제 있음) (0) 2019.07.16
